
In today’s data-driven landscape, the distinction between merely managing data and leveraging it strategically can be the difference between stagnation and growth. DataOps and MLOps are not just buzzwords; they represent a transformative shift in how data teams operate, integrating data management with business goals to enhance productivity, reliability, and ultimately, business outcomes.
DataOps, at its core, is about streamlining the data analytics process from the initial data ingestion to actionable insights. This involves data collection, integration, processing, and quality assurance. Traditionally, data teams might rely on building Directed Acyclic Graphs (DAGs) using platforms like Databricks to orchestrate these workflows. While effective at a basic level, this approach often remains siloed, focusing heavily on the mechanics of data movement and transformation without integrating the broader business context.
MLOps extends this paradigm into the machine learning sphere, covering the lifecycle of ML models from development to deployment and monitoring. This includes experiment management, model training, versioning, deployment, and monitoring. Similar to DataOps, the traditional approach often involves disjointed stages that can lead to bottlenecks, such as model drift and deployment delays, which are detrimental to maintaining the pace of innovation and operational efficiency.
The real power of DataOps and MLOps lies in their ability to align these operational tasks with strategic business objectives. Here are a few illustrative examples:
- Data Ingestion: With poor DataOps, a problem in data ingestion may take hours or days to detect and resolve. With a robust DataOps framework, such issues are either prevented through proactive data quality checks or quickly resolved through sophisticated monitoring tools, minimizing downtime and data loss.
- Model Deployment: In traditional settings, deploying a new model can be fraught with delays and errors, especially when migrating from development to production. Effective MLOps practices streamline this process, enabling safe development workflows and faster rollouts and ensuring that models perform as expected in production environments.
- Error Handling: Without integrated DataOps, an error in data transformation might propagate unnoticed, affecting downstream analytics. With integrated error tracking and automated alerts, issues are promptly identified and addressed, often with automated recovery processes in place.
- Data Quality: Poor data quality can lead to incorrect business decisions. Advanced DataOps includes automated data validation rules that ensure data integrity and accuracy, reducing the risk of decision-making based on faulty data.
The Impact of Strategic DataOps and MLOps
The shift from task-based operations to a strategic DataOps and MLOps approach brings significant improvements in key performance indicators:
- Efficiency and Productivity: Automation and streamlined pipelines reduce manual efforts, allowing teams to focus on high-impact tasks.
- Reliability: Automated workflows and rigorous testing decrease production issues, enhancing overall system reliability.
- Scalability and Innovation: Efficient operations pave the way for rapid scaling and swift innovation, keeping businesses agile and competitive.
In essence, adopting a comprehensive DataOps and MLOps strategy is akin to upgrading from a paper map to a live GPS system in navigation. It not only guides you to your destination but also optimizes the route in real-time, ensuring a smoother, faster, and more reliable journey.
As we delve deeper into the specific architectures and workflows of Trel and Databricks MLFlow in the following sections, we’ll explore how these principles are applied in practice, highlighting the distinct advantages that a well-implemented DataOps strategy can bring to a data-driven organization.
From Theory to Practice: Examining Real-World Architectures
While understanding the principles of DataOps and MLOps is crucial, seeing how these concepts are implemented in practice can provide valuable insights. To bridge the gap between theory and application, let’s examine a real-world reference architecture: the MLFlow architecture as implemented by Databricks.
Databricks MLFlow: A Reference Architecture for MLOps
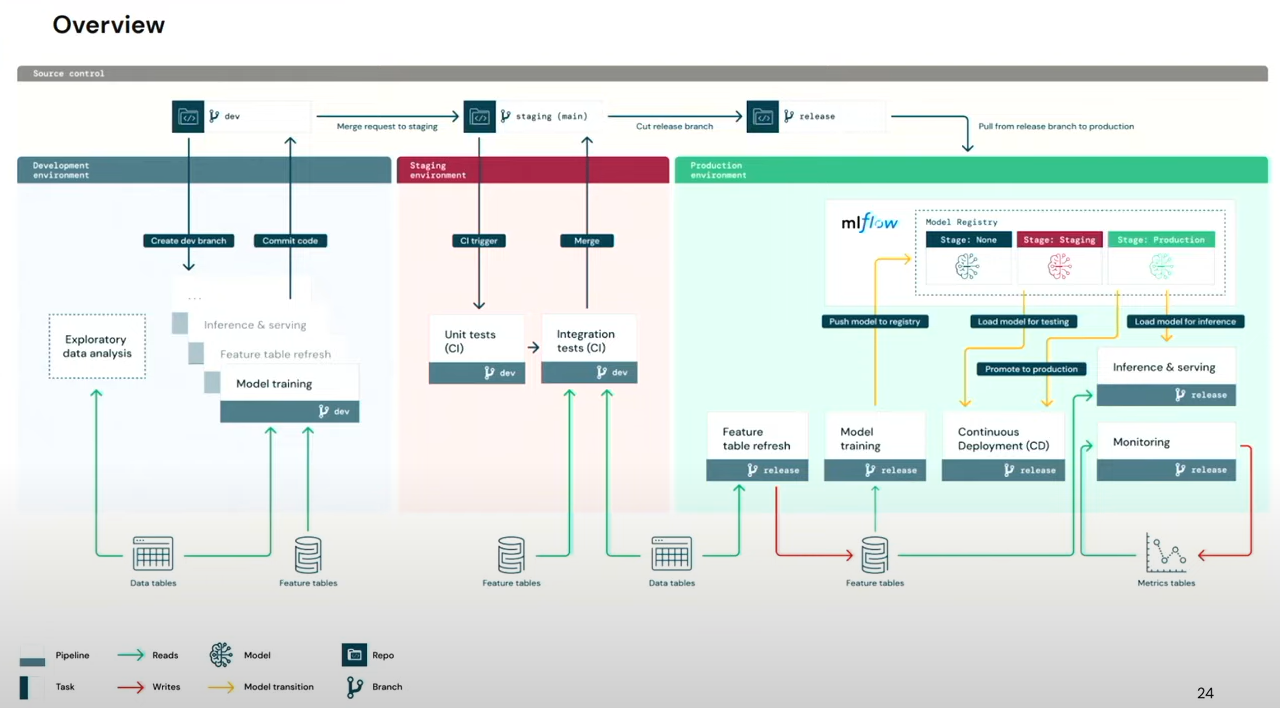
Databricks, a leader in unified analytics and machine learning, has developed MLFlow as a platform for managing the complete machine learning lifecycle. We have taken its reference architecture from A How-to Guide for MLOps on Databricks by Databricks. It starts with the importance of MLOps and DataOps, which we have already covered, followed by a presentation of the reference MLOps architecture involving dev, staging, and prod environments. This is followed by a deep dive into setup and workflows in each environment ending in a concrete example.
Here are some of the slides from the presentation
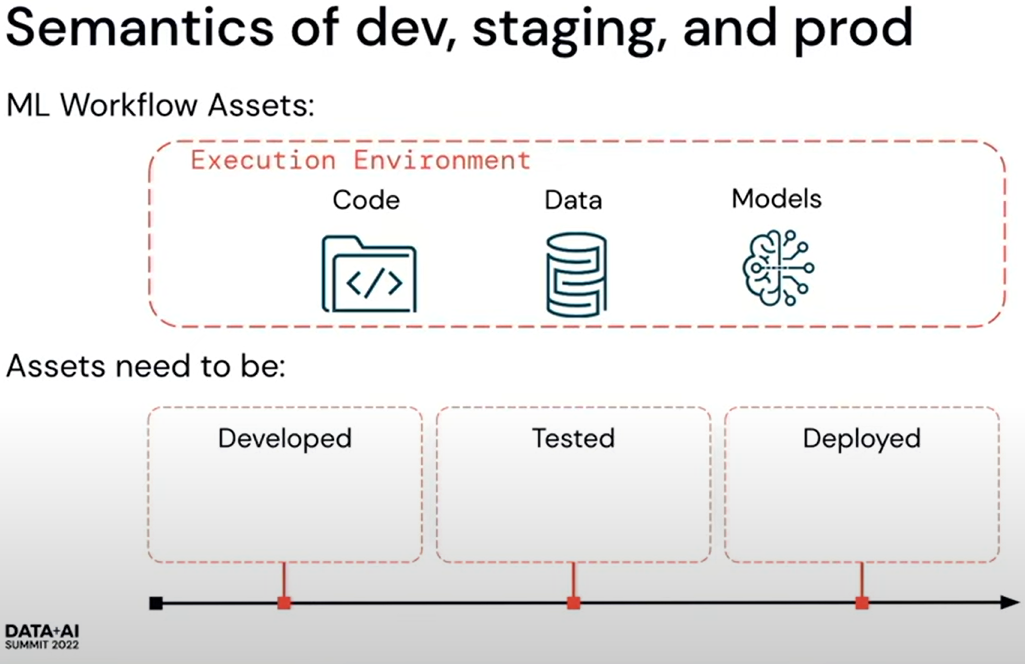
Databricks recommends 3 execution environments viz. dev, staging, and prod with separate data, models, and code where code will be promoted from the dev to staging and then to prod.
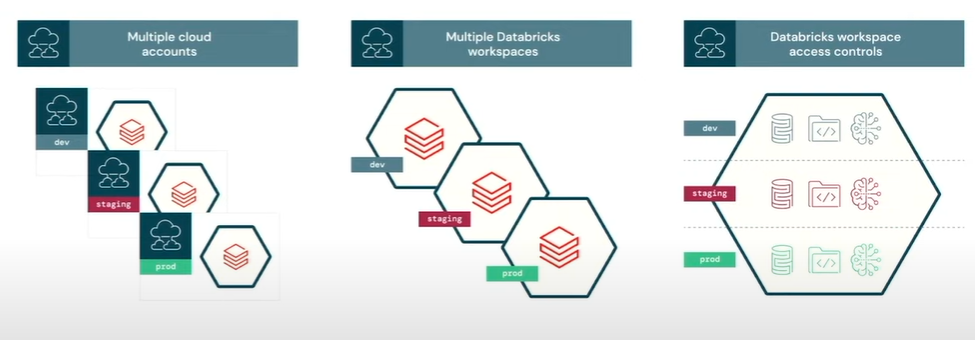
For this organization, Databricks recommends the middle architecture, with separate workspaces for each.
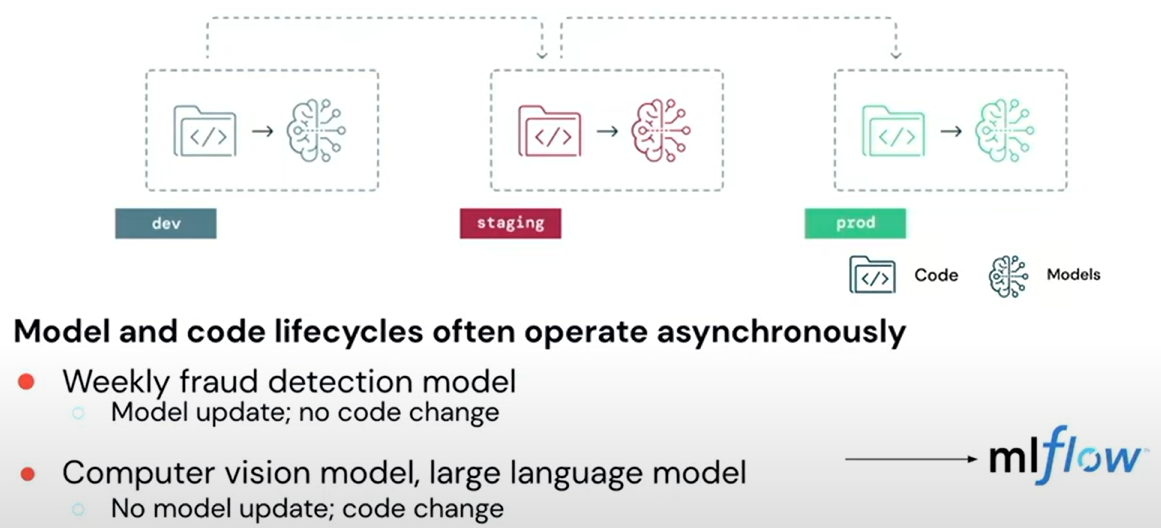
One of the goals of MLOps is to support separate lifecycles for code and data. E.g.:
- Model that is being updated daily, but code is being updated weekly or slower.
- Expensive models that are updated once a few months but where the feature engineering code may be updated more frequently.
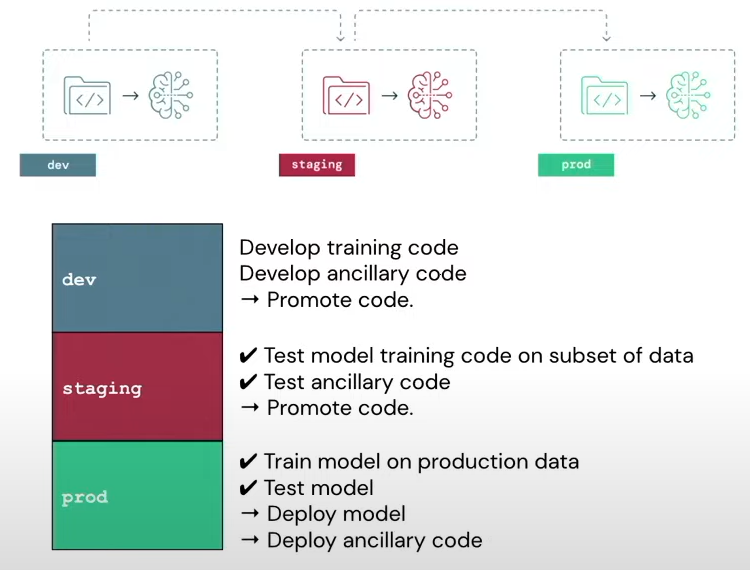
Given above are the various steps that are involved in a typical deployment process. Note the three-step deployment process with testing needed at each stage. An overview of all the stages is given below.
Databricks MLOps Limitations
For this architecture, a few concerns stand out:
- Environment maintenance cost: Maintaining three different environments is expensive due to a lot of duplicated computations that are solely for safety and do not add any business value.
- Prod Data Isolation: Isolating prod data from developers demands additional testing in prod, leading to complicated deployment processes that ensure models function correctly in production. This increases the time-to-data.
- Need for Integration Code: Data science code alone is not enough for production deployment. Automation and integration code must be authored by ML engineers or data engineers, increasing operational costs and complicating and slowing down development processes.
- No Snapshot-Level Lineage: Lineage is tracked at the table level rather than the snapshot level. This requires data engineers to manually examine Delta Lake snapshot entries to determine the actual lineage.
- Slow, Synced Deployments: The use of a single development environment shared by all complicates testing changes without disrupting others’ pipelines. It also necessitates synchronous deployment of integration code rather than ad-hoc deployments. This often results in a time-to-data that far exceeds the time taken to write the actual business logic. Ideally, business logic should be deployable within minutes, not weeks.
- Incompatibility with Notebooks: This architecture is not compatible with Notebooks and requires committed files. Developing in notebooks and converting them to PySpark files (and back for improvements) is a major source of costs, delays, and errors.
- Scheduled Jobs Limitations: All jobs within this pipeline are scheduled. Scheduled DAGs make assumptions about clock time and job completion, which do not provide the precise state tracking needed to ensure correctness during delays or exceptional circumstances. This leads to typical data quality issues such as:
- Data corruption and incompleteness (unless Delta Lake is correctly employed)
- Inaccurate date or date ranges for inputs
- Cascading failures
- Inaccurate data caused by duplicate runs
See our Data Reliability blog post for a deep dive into reliability challenges caused by scheduled jobs. While these are typically caused on the data engineering side, they impact the models and underline the importance of good automation practices for MLOps.
Introducing Trel: A New Approach to DataOps and MLOps
After examining the limitations of traditional DataOps and MLOps approaches, including those of Databricks MLFlow, it’s clear that there’s room for improvement in how we manage and operationalize data and machine learning workflows. This is where Trel enters the picture.
Trel is an innovative platform that builds upon the foundational concepts of DataOps and MLOps while addressing many of the challenges we’ve discussed. It’s designed to integrate seamlessly with existing compute technologies like Athena, PySpark@EMR, and Databricks notebooks, as well as ETL tools like Meltano.
What sets Trel apart is its novel approach to data management, state tracking, job automation, and environment management. These innovations directly address the limitations we identified in traditional systems:
- Immutable Data Practices: Trel implements immutable data strategies to enhance data integrity and traceability.
- Advanced Data Snapshot Catalog: This feature introduces a multi-dimensional approach to data identity, improving data organization and accessibility.
- Data Availability-Driven Automation: Trel’s job triggering mechanism is based on data identity availability, reducing errors and improving efficiency.
In the following sections, we’ll explore these Trel innovations in detail and compare them to the Databricks MLOps approach we discussed earlier. This comparison will highlight how Trel’s features address the limitations of traditional systems and offer a more streamlined, efficient approach to DataOps and MLOps.
Trel Innovations
Trel integrates advanced DataOps/MLOps capabilities with compute technologies such as Athena, PySpark@EMR, and Databricks notebooks, and ETL tools like Meltano. Within Trel, we make a few key innovations regarding data management, state tracking, job automation, and environment management that address all the above concerns.
Immutable Data
Immutable data practices are a cornerstone of modern data engineering. This practice ensures that once data is successfully written, it cannot be updated or overwritten. This means all job executions write to a clean location, creating a new table or dataset.
Many job runs naturally create a new table upon execution. However, for the following scenarios where a new table will not be created, let us examine how data immutability can be achieved.
1. Table Updates: A table being updated periodically, say daily, is a frequent pattern in data automation. The table could be a metric store, feature store, or just a dimension table in a data warehouse. In all cases, each daily update changes the identity of the data in the table. To achieve immutability, the output of each update job is a new table that is recognized to have a different identity than the previous one.
2. Repeated executions: When we repeat a job, typically, the re-run will overwrite or replace the existing table. However, under immutability, this is not allowed and the re-run will create a new table. Contrasting with the table update case, here, the original and new tables are both expected to have the same identity, the difference being only correctness or validity.
The above section introduces the concept of Data Identity: A set of metadata that help users and code understand the context and interpretation of the data. To successfully achieve immutability, both the data catalog and automation must be able to recognize the identity of the immutable tables from these situations and take action accordingly. The next two Trel innovations address these needs and offer additional benefits.
The benefits of immutable data are as follows
- Automatic Error Recovery: Immutable data allows for quick recovery to previous states in case of errors, ensuring data accuracy is maintained. This can be done automatically, eliminating data corruption and interrupted data updates.
- Traceability and Auditing: Every change to the data is tracked, making it easy to audit and verify data changes over time.
- Reliable Machine Learning Models: Consistent data snapshots ensure that the same dataset can be repeatedly used for training models, enhancing model reliability.
- Simplified Version Control: Managing data versions is streamlined as each change creates a new, permanent record of the data.
- Consistency for Collaboration: All users access the same version of data, eliminating conflicts and ensuring consistent data views across teams.
- Time-travel Querying: Historical data versions are accessible for analysis, allowing queries across different time states of the data.
- Simplified ETL Processes: Reduces complexity by eliminating the need to track and manage incremental data changes, leading to more robust data pipelines.
Data Snapshot Catalog with Data Identity
As mentioned earlier, we need to keep track of the identity of each immutable dataset along with the state such as validity and readiness. To facilitate this, Trel introduces a robust solution through its snapshot catalog system. This system is designed to manage data snapshots effectively by organizing them into a structured multi-dimensional space of identities, ensuring that only valid and correctly identified data is available to catalog users and automation.
The effectiveness of this snapshot catalog hinges on the precise definition of data identity, which Trel structures along four key dimensions:
- Dataset Class:
- Equivalent to traditional table names
- Specifies the dataset type or class, facilitating quick identification and appropriate handling of data types
- Example: “Customers”, “Orders”, “ProductInventory”
- Instance:
- Marks the dataset with a specific temporal or logical instance, typically just a date, ensuring traceability over time
- Example: “2023-12-31”, “storeId=345,2024-02-04”
- Label:
- Indicates the environment or experiment the data is associated with, allowing for segmented analysis and controlled testing scenarios
- Example: “prod”, “dev”, “experiment_A”
- Repository:
- Determines where the data is stored and under what access conditions, crucial for data security and compliance
- Example: “data-lake”, “secure-pii”, “data-warehouse”
All immutable datasets created as a result of job executions will be assigned an identity from this space as decided by the job creator. For example, (Customers, 2023-12-31, prod, data-lake) could represent the master list of customers as of the end of 2023 in the production environment, stored in the main data lake.
Furthermore, this identity space is unique for the actionable portion of the data snapshot catalog. This way, the snapshot catalog acts as a Single Source of Truth (SSoT) regarding what data currently holds a specific identity. Months or even years later, users and code can retrieve the data mapped to this identity from the catalog and have access to the correct historical list of customers.
By completing the implementation of immutable data, Trel’s snapshot catalog offers the same benefits. In addition, the following benefits are added:
- Enhanced Data Accessibility: The structured catalog makes it easier for users to locate and access specific data versions, thereby improving the efficiency of data retrieval processes.
- Improved Data Security: By clearly defining where data is stored and under what conditions it can be accessed, the catalog helps enforce security policies and ensure data compliance with industry regulations.
- Efficient Resource Management: The catalog provides a clear overview of data usage and storage, allowing for more effective resource allocation and cost management.
- Proactive SLA Management: The catalog monitors the presence, health, and quality of data identities. It can trigger alerts if expected identities are missing or if data quality issues are detected, ensuring high data integrity. Unlike job failure alerts, Trel’s SLA alerts are persistent until remediation, ensuring data trust.
- Customizable Data Views: Users can configure views of the data catalog that align with their specific project needs or operational roles, enhancing personalized access and usability.
- Conflict Resolution: By maintaining a clear record of data changes and versions, the catalog helps resolve conflicts that may arise from concurrent data accesses or updates.
- Regulatory Compliance and Reporting: The detailed tracking and structured organization aid in meeting regulatory requirements, making audits and compliance reporting simpler and more transparent.
- Decision Support and Analytics: The ability to track and analyze historical data changes supports better decision-making and can uncover insights that are obscured in less structured data environments.
Automation Driven by Data Availability
We mentioned that code can also benefit from the data organization in the snapshot catalog based on the 4-dimensional identity space. Rather than leaving it to the user to write custom code to poll the catalog for the correct condition, Trel introduces a new mechanism for job triggering based on data identity availability.
Each data job is configured to execute only when its specified input datasets, defined by their identity classifications described above are present in the data snapshot catalog. This can be expressed as a formula similar to a spreadsheet formula
For example, suppose we want to automate a job called churn_features that reads Customers, Billing, and SupportTickets tables. This job can be automated using the following formula:
(Customers, <DATE1>, prod, dl) + (Billing, <DATE1>, prod, dl) + (SupportTickets, <DATE1>, prod, dl) -> (churn_features, <DATE1>, prod, dl)
Trel can convert this formula into a trigger on the data snapshot catalog so that when the right conditions are met, it can automatically run the churn_features job while providing the correct inputs from the catalog. This method ensures that each job operates on the data with the correct and only proceeds when all necessary conditions are met.
This formula-based approach offers the following advantages beyond what are explained above:
- Lineage Tracking: Every job’s input and output data are meticulously cataloged, making it easy to trace the lineage of data transformations. This detailed tracking helps in understanding data provenance and simplifies debugging and auditing processes.
- Prevention of Cascade Failures: By ensuring that each job executes only when its specified inputs are verified in the data catalog, Trel minimizes the risk of cascading failures. This setup prevents subsequent jobs from processing incorrect or incomplete data, thereby maintaining system integrity.
- Enhanced Scalability: The system’s ability to manage dependencies dynamically allows for robust scalability. As operations grow, Trel handles the increasing complexity without needing manual intervention, ensuring that jobs are triggered promptly as soon as their data prerequisites are met.
- Immunity to Duplicate Run Challenges: Trel’s unique identity system for data ensures that even if a job is executed multiple times, only the latest and correct version of data is retained. This avoids redundancy and maintains data integrity by preventing duplicate data entries.
- Data Consistency and Accuracy: By utilizing specific identity parameters for each job’s input and output, Trel guarantees that only the correct datasets are used for operations, ensuring data accuracy and consistency throughout the workflow.
This methodological shift not only aligns with best practices in data management but also provides a foundation for more advanced data operations, including real-time processing and complex data orchestration across multiple environments.
Trel DataOps / MLOps
With the support of the above innovations, Trel can define a more streamlined DataOps/MLOps process for the data team.
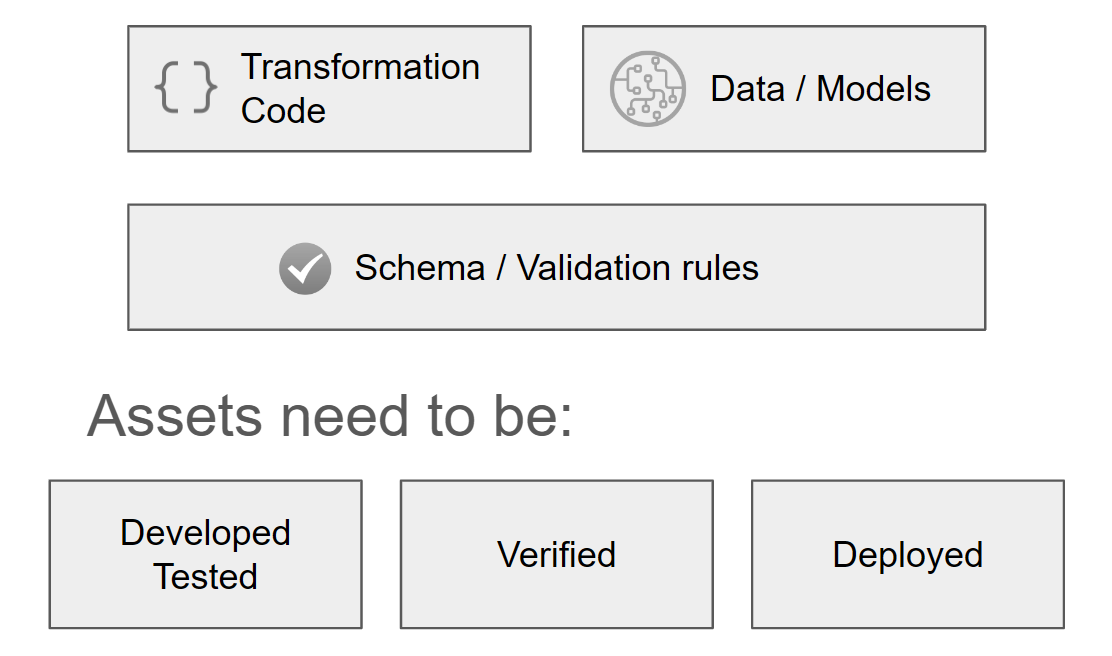
The first major difference is that we store and organize schema and validation rules for each dataset class as part of the platform rather than within the integration code as specified by Databricks. We also provide API for performing the validation, virtually eliminating the need for integration code.
Repositories for data access & Labels for deployment
One pattern we notice in Databricks deployment architecture is that the dev-staging-prod separation is primarily for deployment safety. There are no guidelines for managing or restricting certain types of data, say PII, during deployment.

With Trel, instead of the traditional dev-staging-prod, you get two complete dimensions to organize your data as you see fit.
The Label Dimension is a more flexible implementation of dev-staging-prod. Permission to write to a label is enforced by the Trel catalog, providing safety for prod label.
The Repository Dimension, on the other hand, controls data storage locations. E.g, data-lake and data-lake-pii could be two separate repositories defined in your data lake. They map to different root storage locations, allowing only a minority of users to have read/write access to the data stored under the latter.
Of course, Trel runs all jobs based on the registering user’s credentials, preventing jobs from accessing data its owner has no access to.
Deployment workflow
For development and deployment, we follow a workflow similar to normal code development involving feature branches, pull requests, and merges. Despite this, we support development and deployment directly using Databricks Notebooks, eliminating the time-consuming step of porting notebook code into Python files and vice-versa.

The deployment workflow for Trel takes advantage of the label column and data immutability.
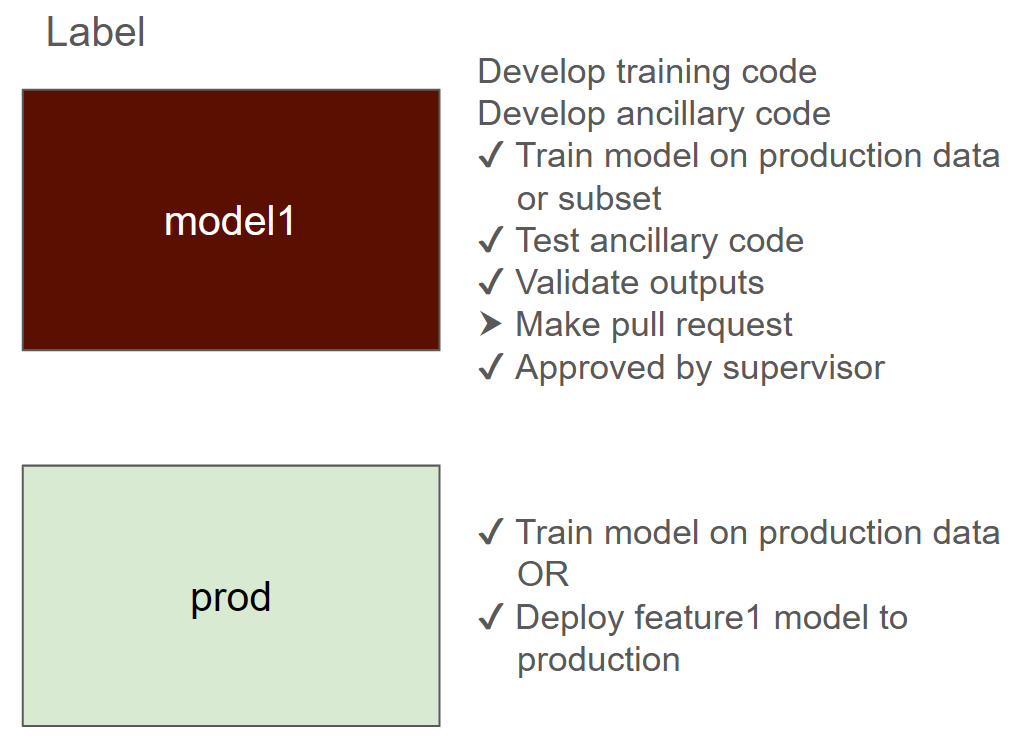
1. Decide on a new label for the new job or modification you are working on.
2. Enter schema and validation rules for the output into the Trel platform.
3. Write a job configuration with a formula where you read from production and write to this label. Have this job run from a code branch with the same name as well. Reading from production is safe due to data immutability.
(Customers, <DATE1>, prod, dl) + (Billing, <DATE1>, prod, dl) + (SupportTickets, <DATE1>, prod, dl) -> (churn_features, <DATE1>, churn, dl)
4. Execute the job as many times as needed, while making the API call for schema and validation on the output. The snapshot catalog will suppress the duplicate copies of the output.
5. Once the output in the churn label is satisfactory, submit a pull request noting the feature label and code branch.
6. The supervisor reviews the code, data, and corresponding schema and validation rules before approving the pull request and merging the code.
7. Re-register the job to use the master branch code and output to the prod label. This will run in production and produce production data. The output from the churn label can also be copied over to the prod label if data is needed in production immediately.
For this workflow, the code that must be written as part of the Databricks notebook is streamlined to largely consist of business logic only. Here is a notebook performing some simple data deduplication that is fully automated using Trel.
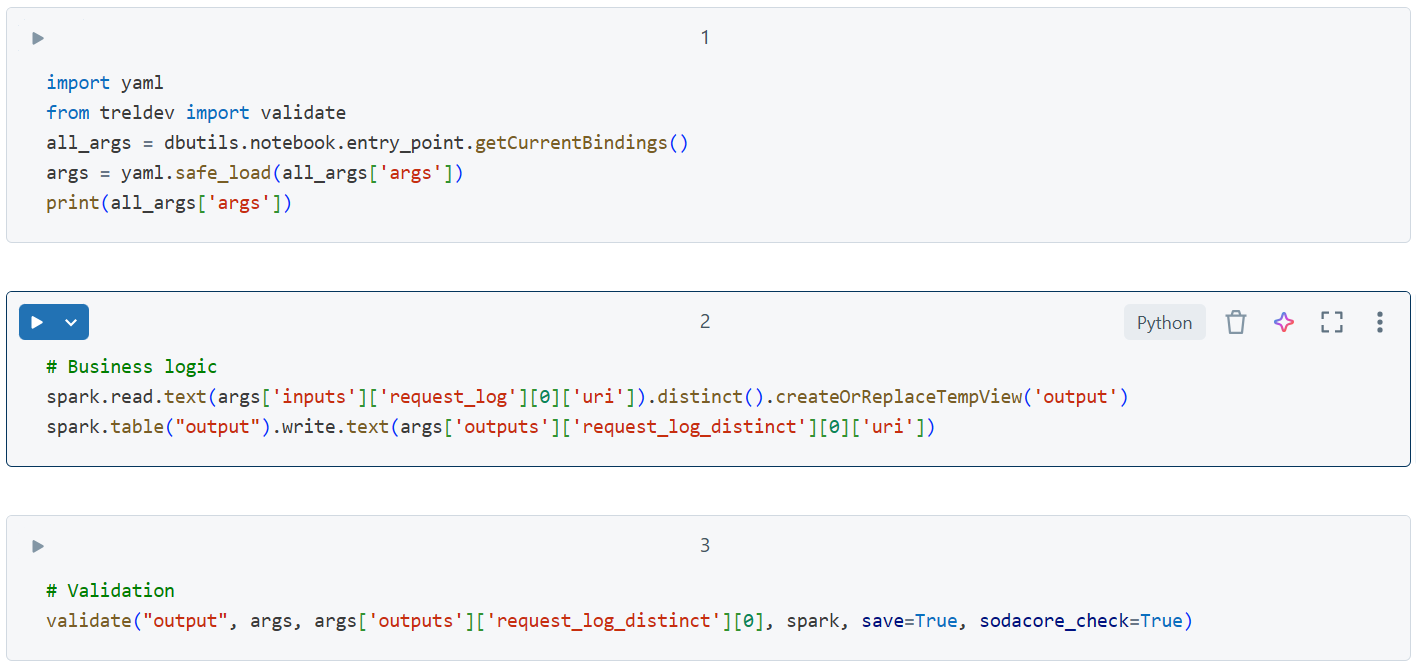
Due to the absence of integration code, there is a reduction in code complexity as well:

The new deployment diagram is vastly simpler than before and executable by every member of the data team.
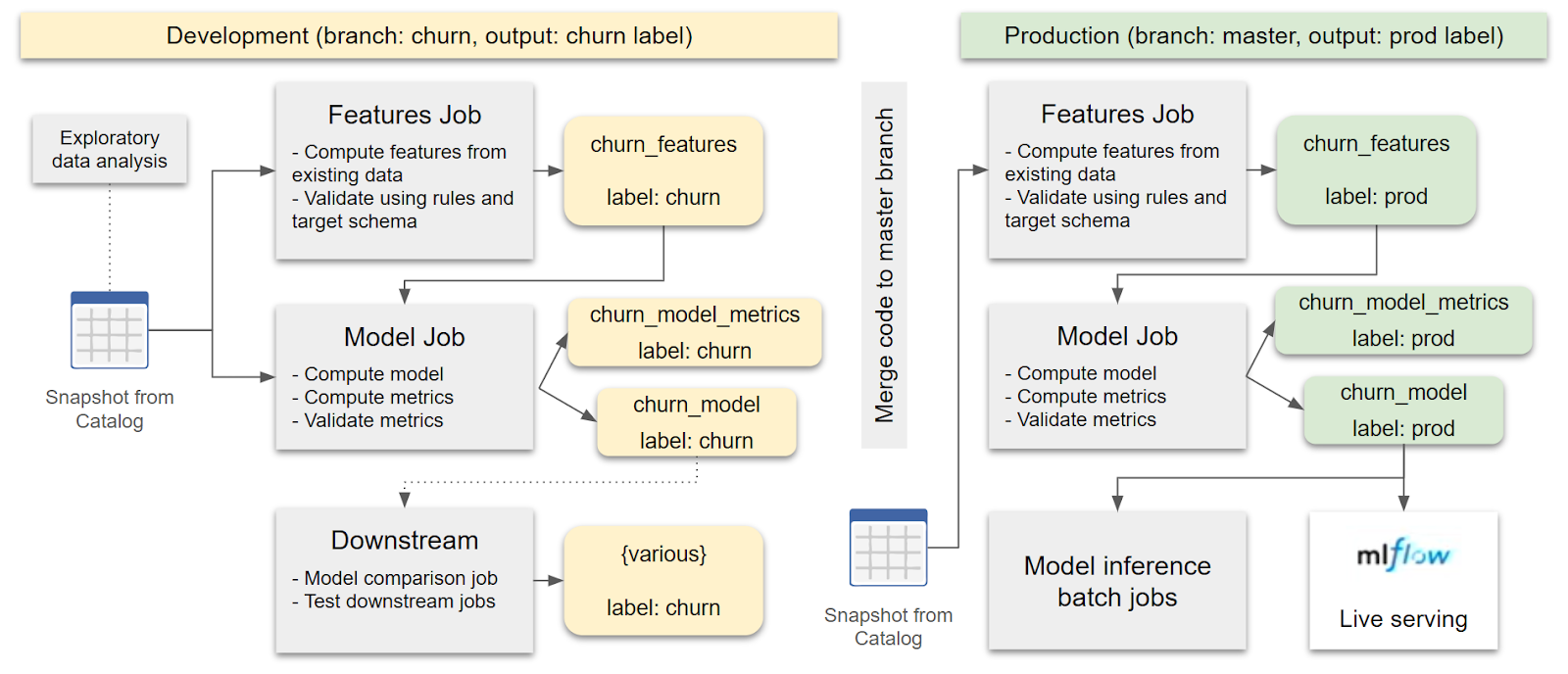
Final Comparison
Compared to Databricks alone, relying on Trel for data cataloging and automation offers substantial benefits summarized below.
| MLFlow | Trel | Impact |
| Job scheduling is error-prone | Job dependencies are resilient and reproducible | ⬆ Quality |
| Lineage at table level | Lineage at the snapshot level | ⬆ Quality |
| Requires business logic and automation code | Only modular business logic is needed | ⬆ Productivity |
| Reference workflow requires .py files | Can work directly off of Databricks Notebooks | ⬆ Productivity |
| Collaboration needs continuous integration testing of code and data | Integration by data catalog upon schema verification + data validation | ⬆ Collaboration |
| Deploy within the agile release cycle (2 weeks) | Deploy business logic immediately | ⬆ Responsive |
| Complex 3-step deployment | Easier 1-step deployment | ⬆ Productivity |
| ML engineer recommended | Minimal need for an ML engineer | ⬆ Cost Savings |
| You have to figure things out yourself | Free solutioning and support | ⬆ Productivity |
This illustrates the substantial advantages of leveraging Trel over traditional DataOps and MLOps practices with Databricks alone. By optimizing workflows, reducing the need for extensive coding, and enhancing data reliability and lineage clarity, Trel empowers your data teams to focus more on strategic business impacts rather than operational complexities.
Conclusion and Future Directions
This article has explored the evolving landscape of DataOps and MLOps, comparing traditional approaches with newer, more integrated solutions. We’ve examined the limitations of conventional systems and highlighted how innovations in data management, such as those implemented by Trel, can address these challenges.
Key takeaways include:
- The importance of immutable data practices for reliability and traceability
- The value of sophisticated data cataloging systems for enhanced accessibility and security
- The benefits of automation driven by data availability rather than rigid scheduling
As the field continues to evolve, we anticipate further advancements in:
- Real-time data processing integration
- Enhanced AI-driven data quality management
- More seamless integration between data science and engineering workflows
For data professionals and organizations looking to stay at the forefront of these developments, continued education and exploration of emerging tools and methodologies will be crucial.
Learn More and Get Involved
If you’re interested in diving deeper into these concepts or exploring how advanced DataOps and MLOps practices could benefit your organization:
- We offer in-depth blogs on our website.
- Our team regularly hosts workshops on cutting-edge data management practices. Reach out to us to join one.
- For qualified participants, we have a Case Study Program that provides access to enterprise-level tools at a reduced cost in exchange for sharing your experience
To learn more about these resources or to discuss how these approaches might apply to your specific data challenges, we welcome you to reach out to our team of experts.
By continually refining our data management practices and embracing innovative solutions, we can collectively push the boundaries of what’s possible in the world of data science and engineering.

