UPDATE: Part 2 has been posted
Salesforce is a popular CRM data tool for support, sales, and marketing teams worldwide.
Companies find it easy to get started with Salesforce on a small scale. But as an organization grows, the need and opportunity to transform, join and validate data increases.
Often many companies rely on Salesforce for all their data processing needs. This is a natural decision because CRM is the most crucial tool for the company when the primary activity is sales.
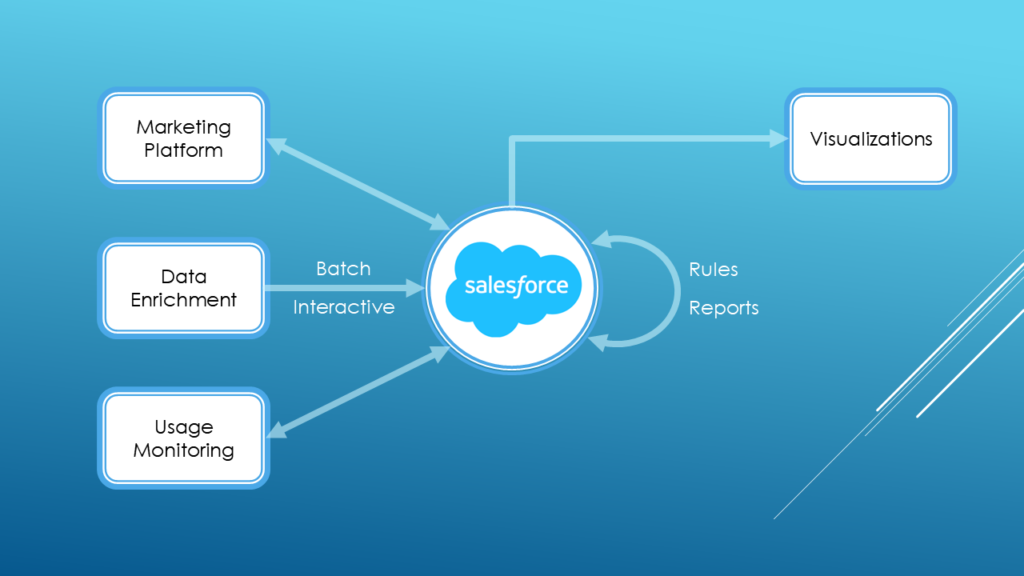
Salesforce can integrate with different types of platforms. E.g., marketing platforms such as Marketo, Mailchimp, etc. There can also be data enrichment done interactively or through batch data.
To get a handle on your data, Salesforce offers:
- Rules: These are code that triggers under certain conditions that developers can write to result in the necessary changes. Developers typically use rules to keep data consistent in response to changes. They can be synchronous (run one by one sequentially) or async (run in parallel).
- Reports: If a summary or analysis of the current state is needed, Salesforce allows you to create reports. They are SQL (salesforce’s flavor of it) and are scheduled.
Salesforce admins and developers focus on meeting the company’s needs by creating rules and reports. This has a crucial benefit. As rules are near real-time, their impact is immediately visible. E.g., if you need specific actions to result in an updated dashboard, a rule can update the dashboard dataset as soon as the action is taken. This is the ideal behavior.
Challenges in processing CRM data in Salesforce
However, relying on rules and reports leads to several challenges:
- Performance limitations: If the rule runs in real-time, it cannot do complex table scans, window functions, or sophisticated processing. That would slow down the Salesforce instance for all users. So, you are required to look elsewhere for such transformations and mappings. Reports have more freedom, but there is still a limit to the computational resources in the Salesforce instance alone.
- Data to join must be loaded into Salesforce: If you want to do the join in Salesforce, the table must be imported to Salesforce. This can have some challenges:
- Data scale: Salesforce has several limits related to external data, which are strictly enforced. The more you try to load intermediate data into Salesforce, the higher the likelihood you will run into these limits. Also, storing large amounts of external data in Salesforce is not practical from a cost perspective.
- Data type and technology: In Salesforce, data is restricted to structured. If you have unstructured data, you are out of luck. You are also forced to use SQL for any joins.
- Data orchestration: If you have a pipeline into Salesforce, it must be orchestrated correctly, even during pipeline disruption. Corrupt and incomplete data getting pushed to Salesforce is a common issue. For orchestration, the tolerance for mistakes is low as you directly load data to a transactional data store (Salesforce).
- Data governance is complex: Ensuring data quality and tracking down data lineage is an important aspect of maintaining a healthy Salesforce instance. Salesforce rules are often not convenient for data quality enforcement. Furthermore, Salesforce offers no avenue for data lineage for rules and reports.
- Data must be exported from Salesforce to investigate and analyze: Salesforce specialists often pull reports from Salesforce as CSV. Then, they work with it using whichever tool is handy and may change some of the data. Usually, the specialist has to import this data back into Salesforce so that the rest of the pipeline can proceed. This is a very time-consuming process and disrupts the workflow of the Salesforce team.
Improved data processing using a data warehouse
Instead, suppose the data transformation and reporting pipelines existed outside of Salesforce. In that case, high-quality tools can: work with the pipeline, make fixes and push the final results directly to the receiver. This offers a streamlined and unified workflow.
To summarize these limitations, Salesforce has limited support as a data warehouse. While rules will still be integral to your Salesforce instance, many problems will be solved if you export Salesforce data to a data warehouse for additional processing. Such a setup allows you to merge your crucial CRM data into your overall data strategy.
The solution is to connect Salesforce to a data warehouse. You will keep some of your rules in Salesforce and some of the integrations. However, reports and custom batch integrations can move to your data warehouse. So can the visualizations.
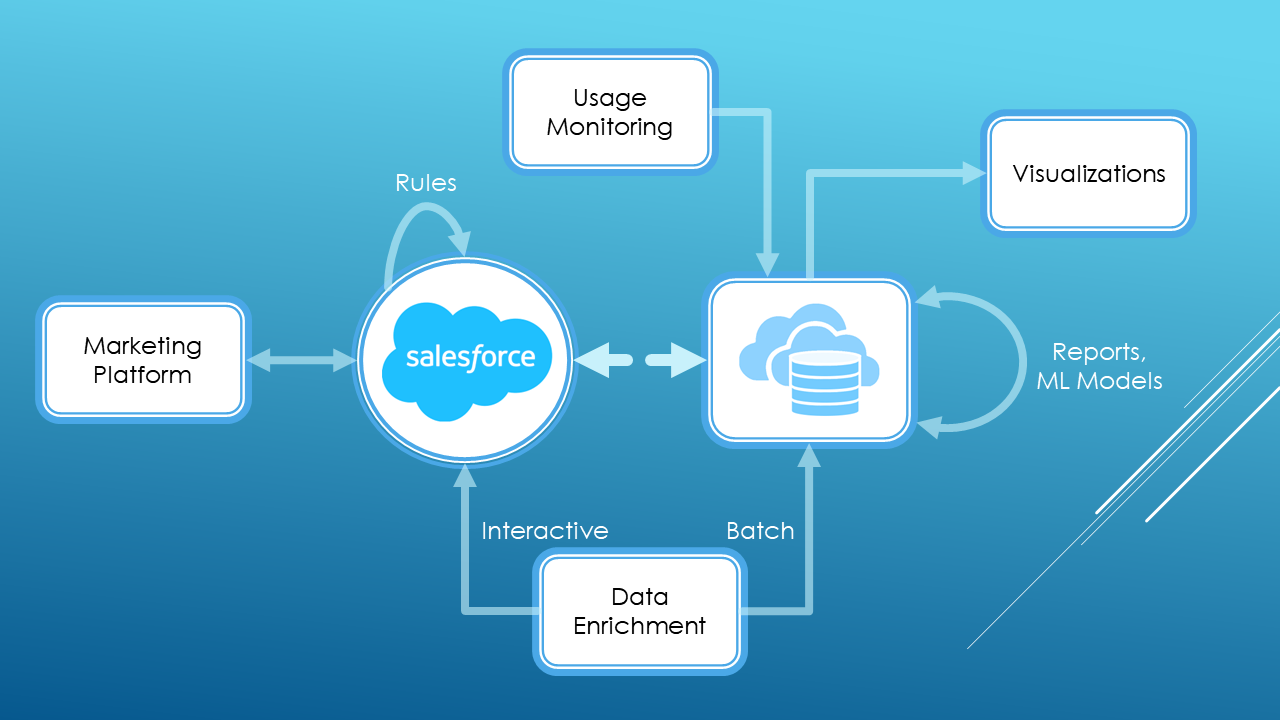
Salesforce with a Data Warehouse
The benefits of pairing up with a data warehouse are
- Easily integrate with other data from your organization
- Be strict in the orchestration of your data processing
- Save cost
- Be able to do machine learning to extract more benefits from your CRM data.
- Use non-SQL languages
- Connect to a wider variety of visualizations
Today, companies’ opinion about data warehouses is that to achieve good reliability and time-to-data, they must spend a lot of money and time on platform development and pipeline creation. This holds companies back from investing in a data warehouse, whether the requirements are Salesforce-centric or far more sophisticated.
But our platform offers a compelling value proposition. In part 2, we detail how to create a new data warehouse with a fully defined architecture in minutes, connect it to Salesforce and start processing your data.