In our previous blog, we discussed how connecting a data warehouse to your CRM (with Salesforce as an example) can improve the performance of your CRM data team. This blog shows you how to connect a Trel data warehouse and Salesforce.
Setup
Trel has SaaS-like pay-as-you-go pricing but is delivered as a fully configured platform based on your requirements. We assume you already have such a configured Trel data warehouse.
Beyond this point, the only setup needed to connect to salesforce is to add the required credentials.
treladmin credential_add salesforce \
'{"username":"[email protected]","password":"__","security_token":"__"}'Bringing the Data In
To bring the data into Trel, we use the Salesforce sensor available in trel_contrib, our open-source collection of reusable connectors.
We are using a sensor that loads Salesforce data to BigQuery. This sensor comes with a sensor registration file, which is what you need to use it. There is no need to change most of it. What we need to examine are these lines:
sensor_id: salesforce
dataset_class_prefix: "salesforce."
table_whitelist:
- User
- Account
- Lead
The table_whitelist specifies which tables to download from Salesforce. The dataset_class_prefix specifies what to call the resulting datasets in the Trel data catalog. sensor_id is the name of the sensor
Once you make the needed changes to this registration file, please commit it to your own repository. After that, run the following command:
trel sensor_register config.ymlThis creates the sensor. However, it is not active yet. So, we activate it.
trel sensor_update salesforce --enableOnce this is done, the sensor starts working, examines Salesforce and the Trel data catalog, realizes that data is missing and can be loaded, and proceeds to load it while cataloging it with metadata that facilitates data discovery and automation.
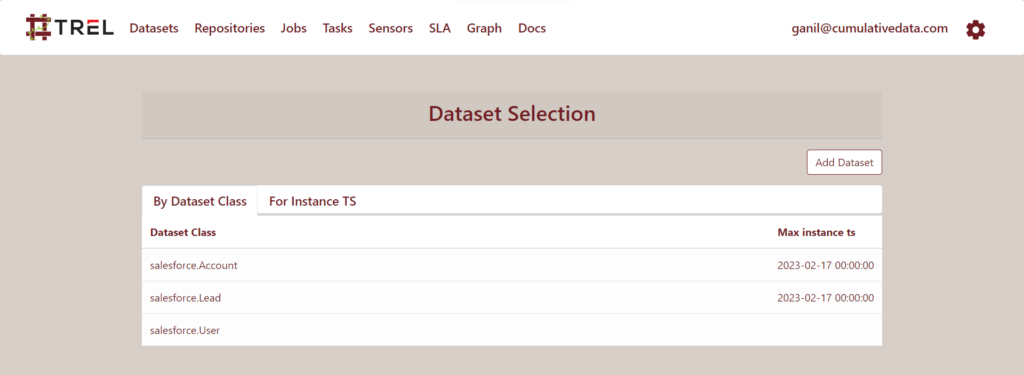
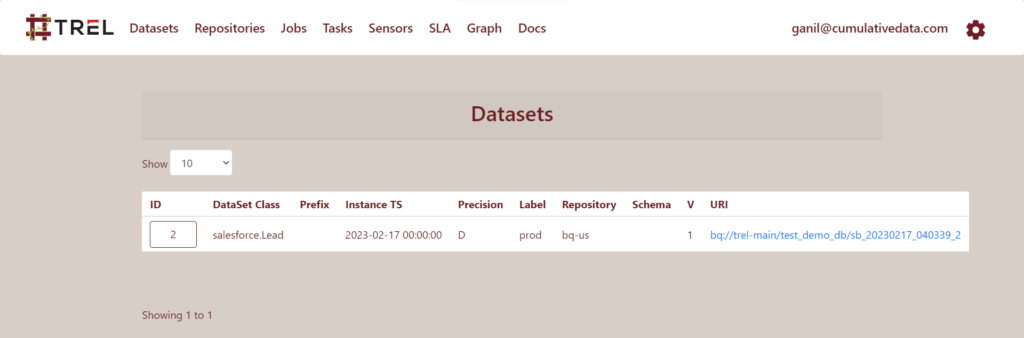
Note how only the paths to the date are added to Trel. The data itself resides in BigQuery.
Analyzing the data
You can click the URI to take you to the resource. In this case, the data was copied to BigQuery. Clicking the link will take you to the google cloud console to examine the data.
Suppose you did some data analysis on the Lead table (dataset_class: salesforce.Lead). You noticed some inconsistencies in the title and decided to standardize it. Rather than just manually fixing it, you decide to write some SQL that covers most cases. The SQL can look something like this:
with
lead as (SELECT * FROM `__table__`)
SELECT *
FROM (SELECT id,
CASE
WHEN title = "Senior Vice President" THEN "SVP"
WHEN title = "Vice President" THEN "VP"
WHEN title = "Regional General Manager" THEN "Regional GM"
ELSE NULL
END as title
FROM lead)
WHERE title is not NULLOur goal is to update the Lead table in Salesforce using the new titles. We have a connector that can modify a salesforce table. For updating rows, this connector needs the ID column and the column to update. This SQL provides both.
We want this SQL to process the Lead table and update it daily.
Converting the analysis to a Job
To start automating this SQL, we have to name all our intermediate datasets. Let us name the output of this SQL salesforce.Lead.fixed_titles.
Next, we need to decide how this SQL is going to run. Trel has several execution plugins. The one for BigQuery is called bigquery and requires you to provide a python executable. So, we parameterize this SQL and wrap it in python.
import argparse, yaml
from treldev.gcputils import BigQueryURI
from treldev import get_args
if __name__ == '__main__':
args = get_args()
schedule_instance_ts = args['schedule_instance_ts']
output_bq = BigQueryURI(args['outputs']['salesforce.Lead.fixed_titles'][0]['uri'])
input_bq = BigQueryURI(args['inputs']['salesforce.Lead'][0]['uri'])
output_bq.save_sql_results(f"""
with
lead as (SELECT * FROM `{input_bq.path}`)
SELECT *
FROM (SELECT id,
CASE
WHEN title = "Senior Vice President" THEN "SVP"
WHEN title = "Vice President" THEN "VP"
WHEN title = "Regional General Manager" THEN "Regional GM"
ELSE NULL
END as title
FROM lead)
WHERE title is not NULL
""")This code should be committed to your version control system. We have it committed to GIT here.
Automation
Next, we have to register this code as an automated Trel job. This involves creating a registration file. Given below is a suitable one for this job.
name: salesforce.Lead.fixed_titles
job_description: "Standardizes titles in salesforce.Lead."
execution.profile: bigquery
execution.source_code.main:
class: github
branch: main
path: [email protected]:cumulativedata/trel_contrib.git
execution.main_executable: _code/complete_pipelines/salesforce_3step/fix_titles.py
repository_map:
- salesforce.Lead: bq-us
salesforce.Lead.fixed_titles: bq-us
scheduler:
class: single_instance
depends_on: [ salesforce.Lead ]
labels: [ prod ]
instance_ts_precisions: [ D ]
cron_constraint: "0 0 * * *"
schedule_ts_min: "2023-01-01 00:00:00"
execution.output_generator:
class: default
outputs:
- dataset_class: salesforce.Lead.fixed_titlesWithout going into the details of how to write this registration file, to summarize, this configuration will result in this job running daily on salesforce.Lead and produce salesforce.Lead.fixed_titles.
Let us register and run this job to produce the dataset with the fixed titles.
trel register trel_regis_fixed_titles.yml
trel execute salesforce.Lead.fixed_titles -s 20230217This run (called a task in Trel) produces the following dataset in the catalog:
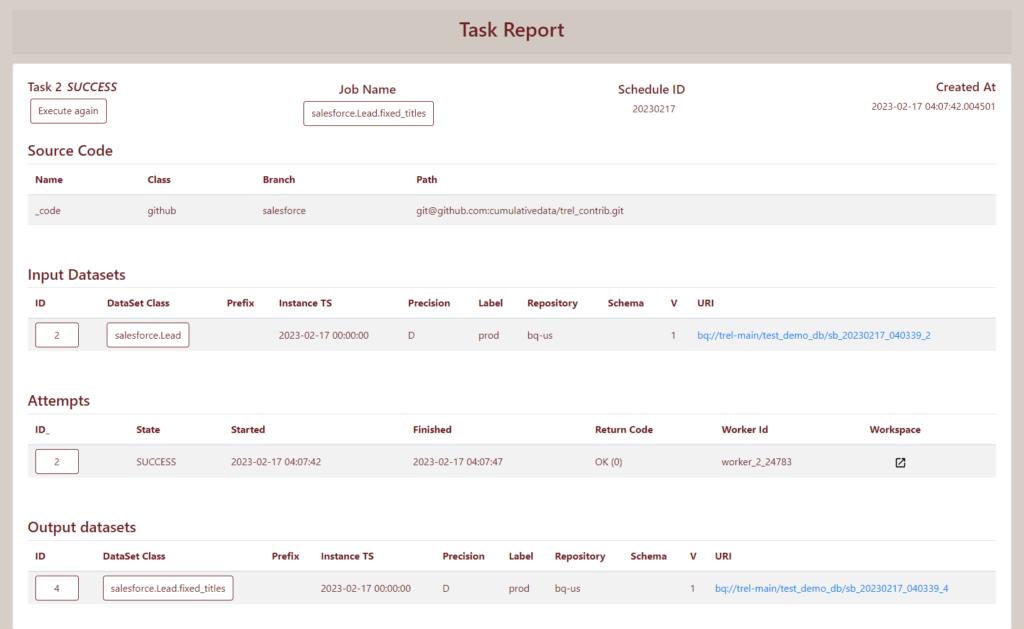
Export to Salesforce
Next, we use the connector code to push this data to Salesforce. For this, we have to register the connector as a job. This requires writing another job registration file.
name: salesforce.Lead.fixed_titles.export
job_description: "Exports Standardized titles salesforce.Lead.fixed_titles to Salesforce"
execution.profile: bigquery
execution.source_code.main:
class: github
branch: main
path: [email protected]:cumulativedata/trel_contrib.git
execution.main_executable: _code/export_jobs/salesforce/gs_to_salesforce.py
execution.checked_out_files_to_use:
- _code/sensors/salesforce/sflib.py
execution.additional_arguments: [ '--target_table=Lead' ]
execution.temp_repositories:
gs: gs-us
repository_map:
- salesforce.Lead.fixed_titles: bq-us
salesforce.Lead.fixed_titles.exported: bq-us
scheduler:
class: single_instance
depends_on: [ salesforce.Lead.fixed_titles ]
labels: [ prod ]
instance_ts_precisions: [ D ]
cron_constraint: "0 0 * * *"
schedule_ts_min: "2023-01-01 00:00:00"
execution.output_generator:
class: default
outputs:
- dataset_class: salesforce.Lead.fixed_titles.exportThe code for the connector exists in our open-source library. Only registration is required.
trel register trel_regis_export_fixed_titles.yml
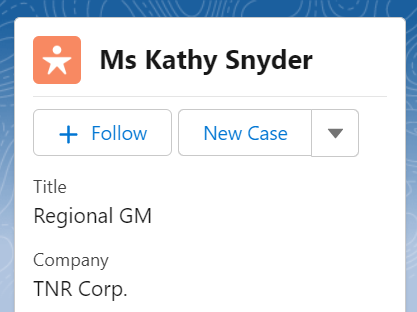
trel execute salesforce.Lead.fixed_titles.export -s 20230217As a result, we can see in Salesforce that the title has been updated from “Regional General Manager” to “Regional GM”.
Summary
Overall, you can see that it is easy to connect your CRM data to Trel. You can quickly implement data transformations directly using cloud platforms and deploy them in Trel. You can also close the loop by pushing the changes to Salesforce.
In the next blog, we will review more complex use cases where Trel can help you improve your CRM data and accelerate time-to-data.