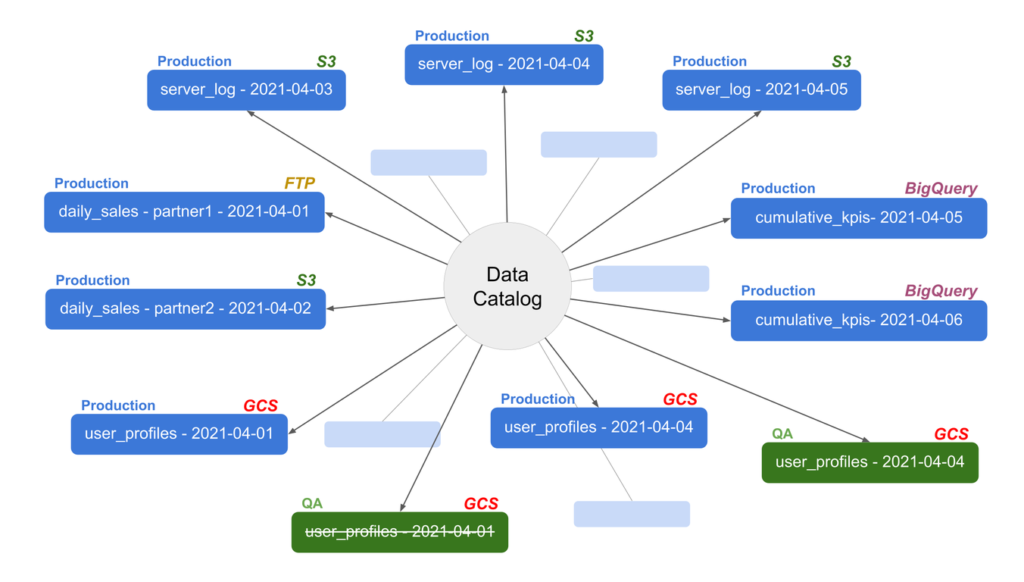
Conquer complexity
Decoupled jobs and code-free dependencies make it easy to scale.

Reliability from Strictness
Formal guarantees on data quality even when jobs fail.

Fix your data with a few clicks
Resolving disruptions is no longer a concern when you have a time-machine.

Research Project
Find Ideas
Start Optimize
Reach Target


it’s easy for marketers to brag about how great their product or service is. Writing compelling copy, shooting enticing photos, or even producing glamorous videos are all tactics
Ethan J.Cooper
Managing Partner, supercheapcar.com
it’s easy for marketers to brag about how great their product or service is. Writing compelling copy, shooting enticing photos, or even producing glamorous videos are all tactics
Jane Doe
Managing Partner, supercheapcar.com


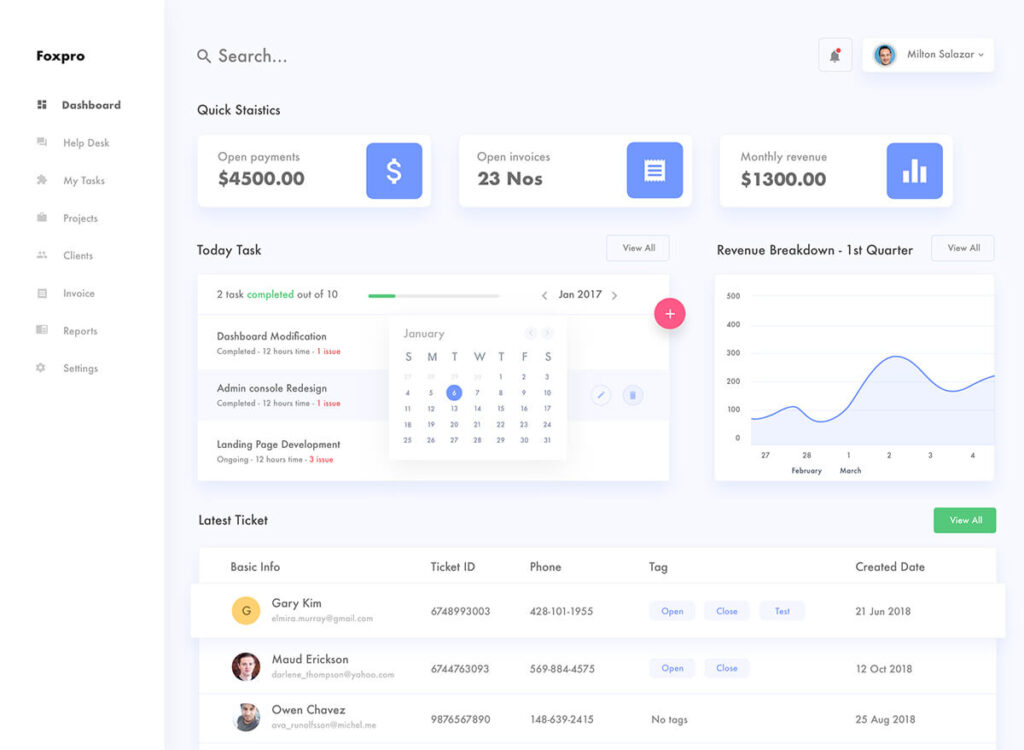
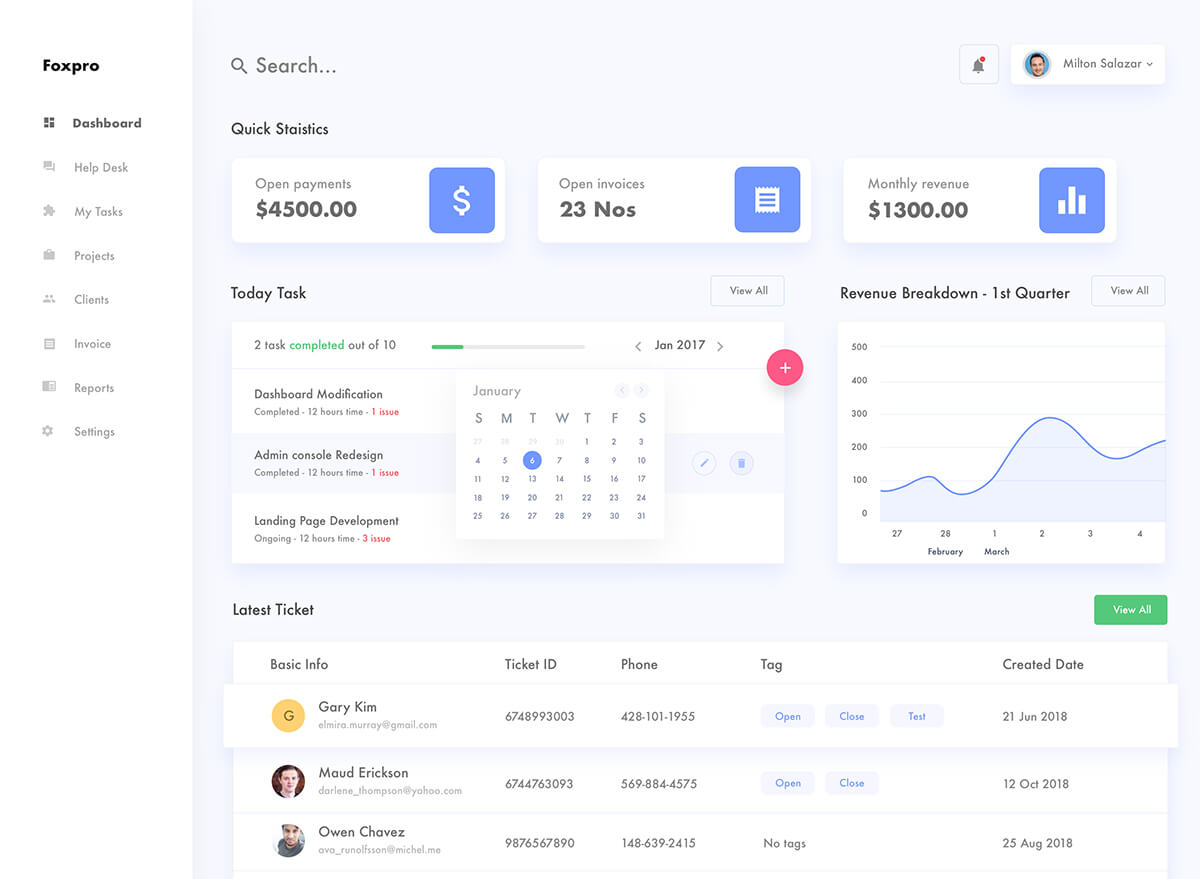




Our efficient data pipeline framework will improve the data competency of data engineers, analysts, and data scientists, making a better world through sound data-driven decisions.
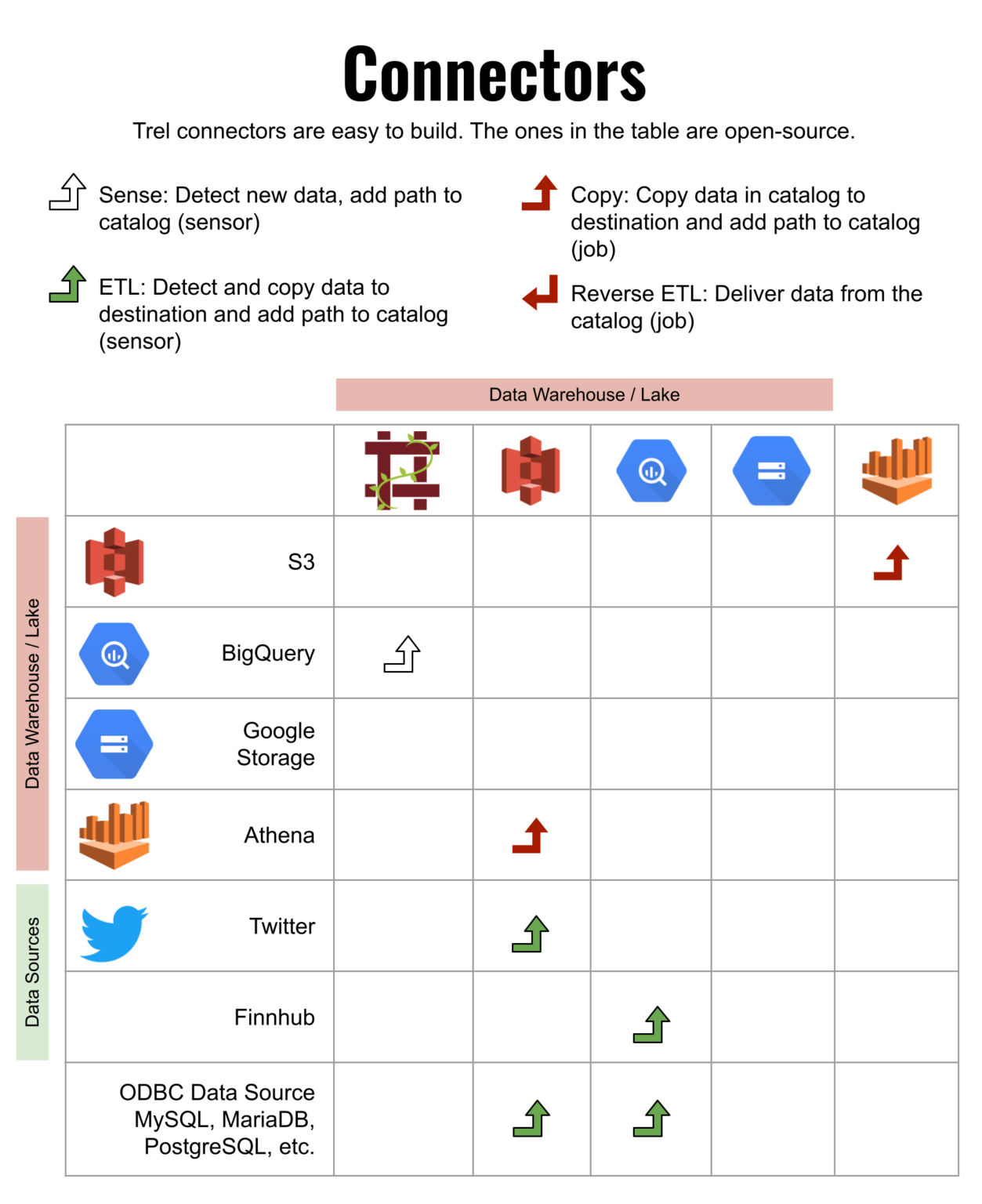
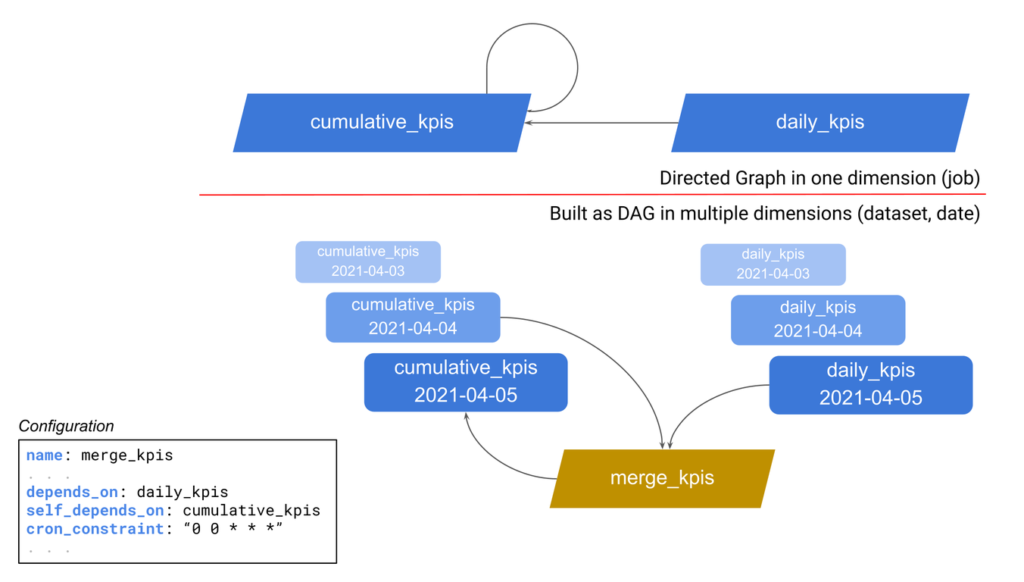
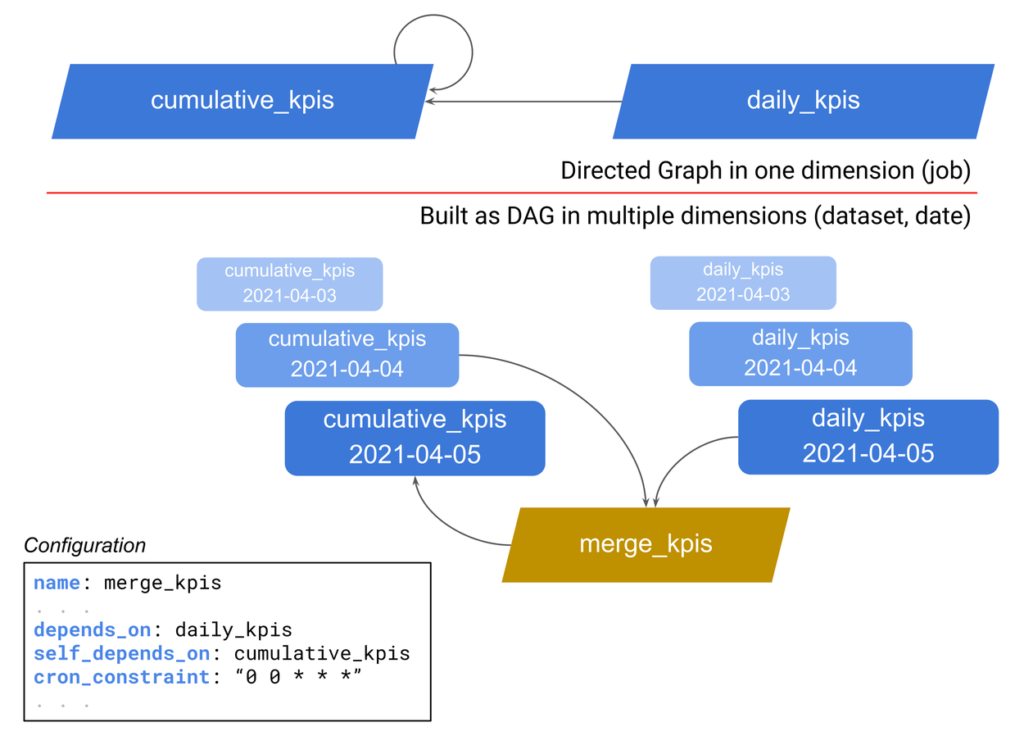
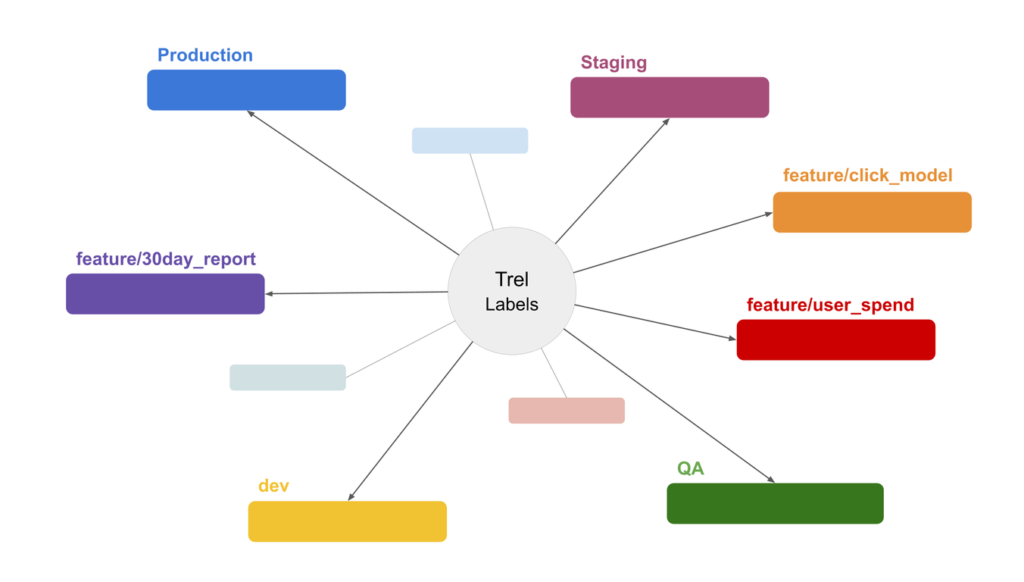
Trel loves complexity
Don't be forced to build a simple data pipeline. Trel makes it easy to do exactly what you want. Complex machine learning workflows? No problem.
Trel says what. You say how
It uses your own business logic to orchestrate your data lake and data pipeline. Trel does not touch your data, the reason why it is truly platform agnostic.
Trel gives power to you.
Trel will feel similar to a well configured shell. Do complex pipeline maintenance with just a few commands.
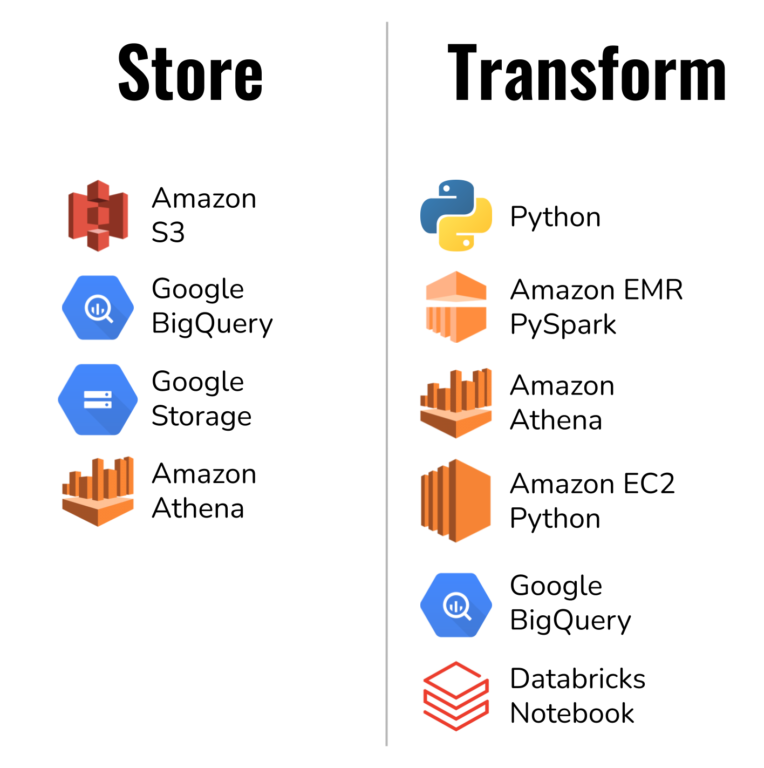
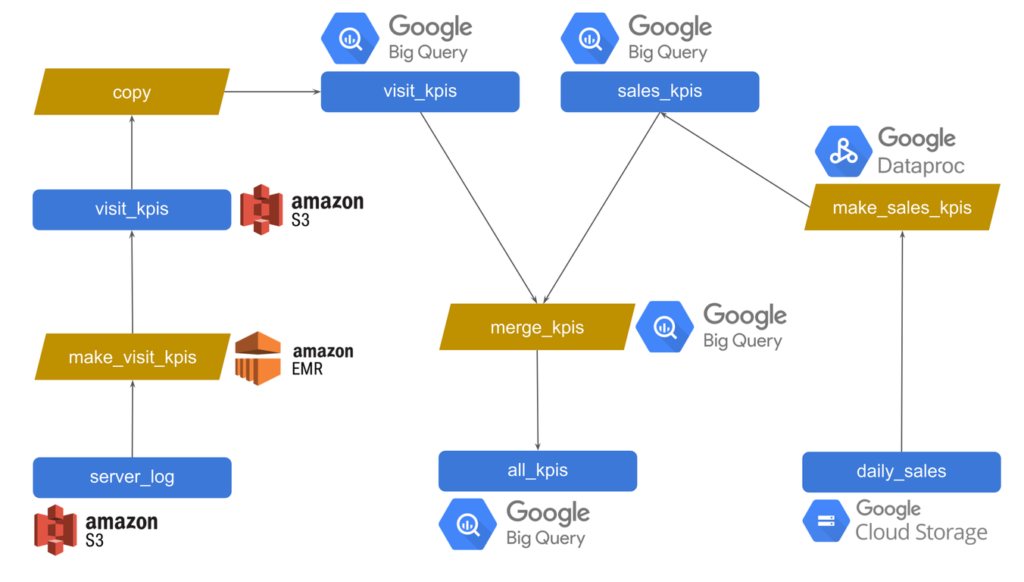
Make your data work hard
Trel shines once your data lands in your data lake. You can build complex and arbitrary data engineering and data science pipelines easily with Trel.